Large Language Models (LLMs) have revolutionised the way we interact with technology, but not all LLMs are created equal. In this blog, let’s explore the two main types of LLMs: Closed loop & Open loop models. We’ll dive into their fundamental differences, examine their pros and cons, and discuss how these differences impact their applications. By understanding the unique characteristics of each model, you’ll be better equipped to make informed decisions about which type of LLM is best suited for your needs. Let’s get started by looking at how these models are built and what sets them apart.
Closed Loop LLM
(Examples: GPT-4 (RLHF), Claude, Gemini, RAG systems)
In a Closed Loop LLM, the model’s self-learning capability is developed and refined through human interaction and usage. This approach is akin to learning through mistakes and corrections by experience. The model adapts and improves based on the feedback it receives from users, which can lead to more accurate and contextually appropriate responses over time.
Characteristics of Closed Loop LLM:
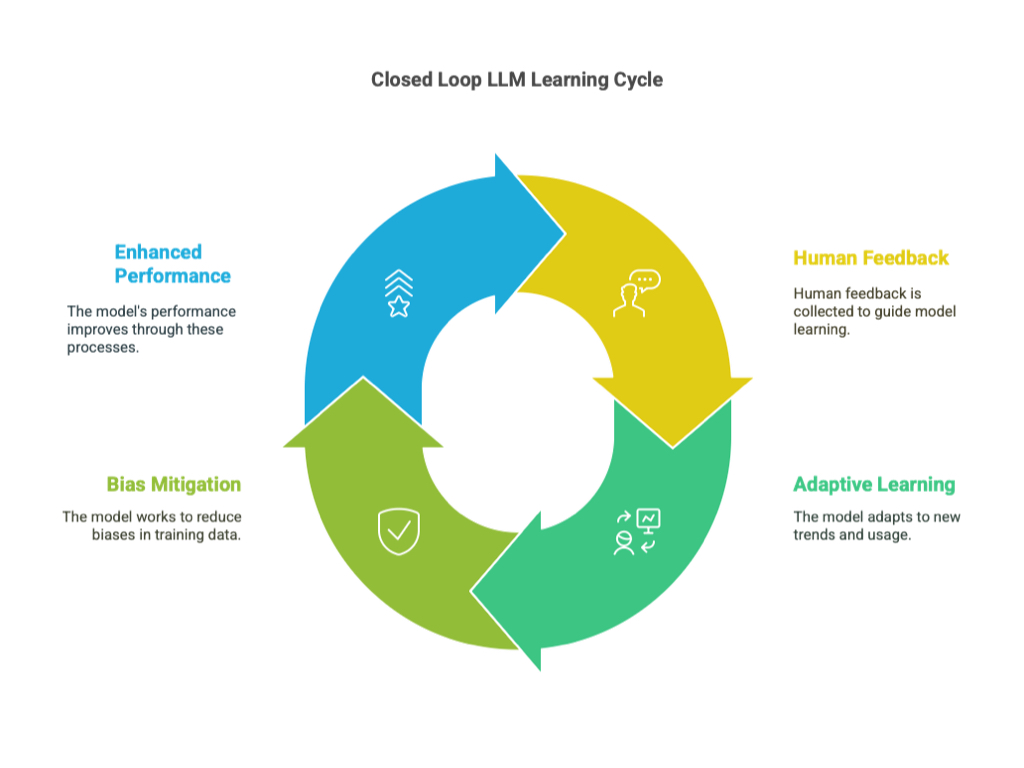
Usage of Closed Loop Models:
• Chatbots with User Feedback Mechanisms: Customer service chatbots incorporate mechanisms for users to provide feedback on the responses they receive, which is then used to improve the model
• Virtual Assistants Learning from User Interactions: Virtual assistants like Siri, Alexa, and Google Assistant learn and improve from the interactions they have with users, adapting to individual preferences and common queries
Closed Loop LLM Examples:
1. Google Assistant’s Personalisation:
• Description: Google Assistant learns from user interactions to personalise responses. For instance, if a user frequently asks about weather forecasts for a specific city, Google Assistant will adapt to provide quicker, more direct answers for that location.
• Demonstrates: Adaptive learning and human-in-the-loop feedback, reducing the need for users to input the same queries repeatedly
2. Chatbots in Customer Service:
• Description: Many companies use chatbots on their websites that learn from customer interactions. For example, if a user frequently inquiries about return policies, the chatbot will improve its responses over time to better address such queries.
• Demonstrates: Human-in-the-loop learning and the potential for reduced bias through diverse customer feedback.
3. Spotify’s Recommendation Algorithm:
Description: Spotify uses a form of Closed Loop LLM to recommend music based on user listening habits. The more a user listens to certain genres or artists, the more tailored the recommendations become.
• Demonstrates: Adaptive learning and the ability to mitigate bias by learning from individual user preferences
Open Loop LLM (Examples: LLaMA 2/3, BERT, RoBERTa, BLOOM, Falcon)
In contrast, an Open Loop LLM relies on its training dataset for its learning and development, with minimal to no adaptation based on user interactions post-deployment. This method can increase the chances of bias and wrongful interpretations if the training dataset is not carefully curated and diverse.
Characteristics of Open Loop LLM:
• Static Learning: The model’s learning is primarily based on its initial training dataset, with little to no adaptation to new information or changing contexts post-deployment
• Risk of Bias and Errors: If the training dataset contains biases or inaccuracies, the model may propagate these issues in its responses, potentially leading to harmful or misleading outputs
• Efficiency in Controlled Environments: Open Loop LLMs can be highly effective in controlled or specific domain applications where the scope of queries is limited and well-defined
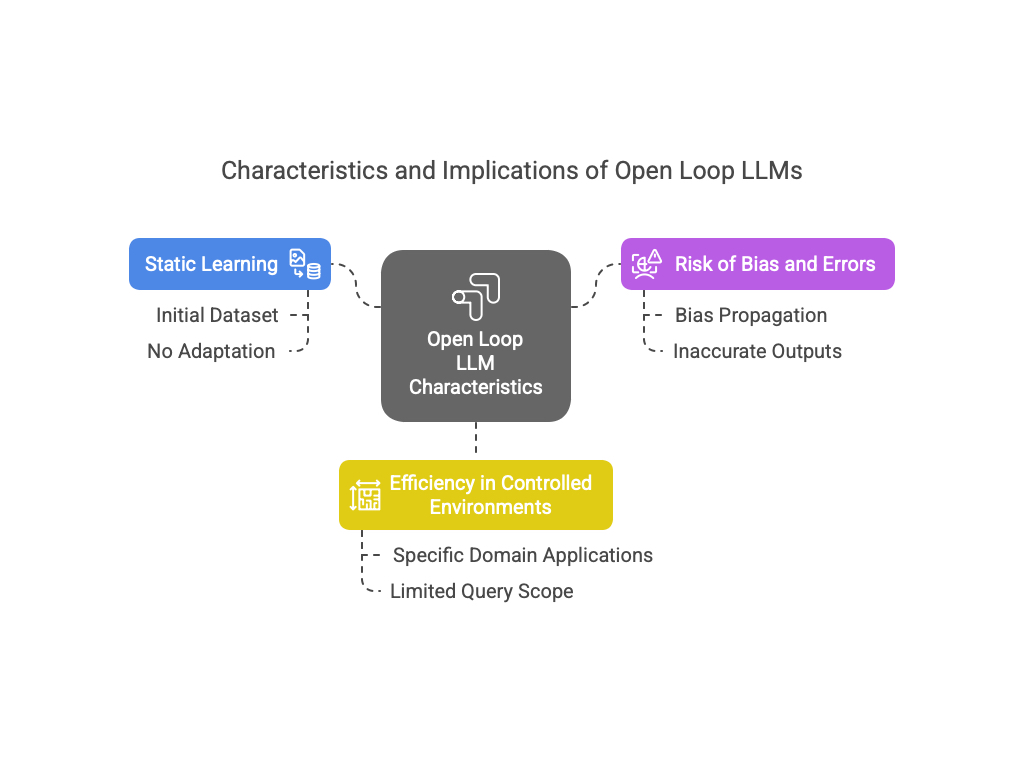
Usage of Open Loop Models:
• Pre-Trained Language Models Without Fine-Tuning: Models like the original versions of BERT and RoBERTa, which were pre-trained on large datasets but not fine-tuned with specific user interaction data, fall into this category.
• Domain-Specific Models Trained on Static Datasets: Models trained for specific tasks, such as medical diagnosis or legal document analysis, based on static datasets without ongoing user feedback loops
Open Loop LLM Examples:
1. BERT for Sentiment Analysis:
• Description: BERT (Bidirectional Encoder Representations from Transformers) was initially trained on a large corpus of text and then applied to sentiment analysis tasks without further training on user interactions. Its performance is based on the patterns learned from its initial training dataset.
• Demonstrates: Static learning and the potential risk of bias if the training dataset does not represent diverse viewpoints.
2. Domain-Specific Medical Diagnosis Models:
• Description: Some AI models are trained on static datasets of medical records and literature to diagnose diseases. These models do not learn from new patient interactions post-deployment.
• Demonstrates: Efficiency in controlled environments and the risk of propagating biases or inaccuracies present in the training data.
3. Legal Document Analysis Tools:
• Description: AI tools used in legal firms to analyse documents are often trained on large, static datasets of legal texts and precedents. They do not adapt to new legal documents or user feedback post-deployment.
• Demonstrates: Efficiency in specific domain applications and the potential for errors if the training dataset is not comprehensive or up-to-date
Conclusion: By distinguishing between Closed loop and Open loop LLMs, developers and organisations can make informed decisions about which approach best suits their specific applications. This choice rests on several critical factors, including the need for adaptability to new trends and user behaviours, the potential for bias in model outputs, and the value of integrating user feedback for continuous improvement. As the landscape of language model deployment continues to evolve, understanding these distinctions will be pivotal in harnessing the full potential of LLMs while mitigating their limitations